“Does your API follow the HBI?” — said every developer ever in the year 2030
 Medium
Medium
Think back to when you started working with APIs. After the initial excitement wore off, think about the frustration that followed. Will it be a hash or an array next, will it be nested? What information will it contain? Asking yourself “All the information is here, but how do I access it?”
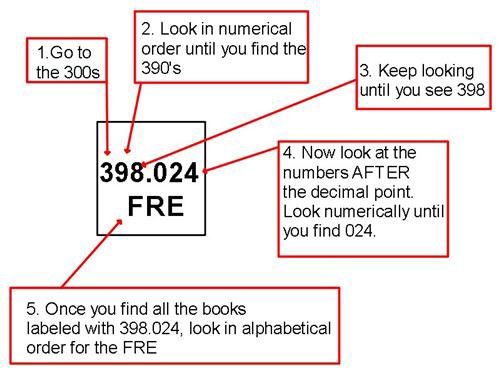
Now imagine the year 1874, you’re a botany scholar studying grass. Grass is the hottest buzz word in the industry right now. New York has an amazing library and you have heard the grass section is top notch. You travel 15 days from your home to reach it and finally arrive.
Pushing open the doors you can’t believe your eyes. More books and information than you could have ever dreamed. So excited you grab the first book, it’s a book about shipping sugar cane. Interesting, but no grass. The process continues until you meet a librarian that knows where the newest books on grass are located. There is no system in place and the books are organized differently than in your home library. You need to ask someone who knows the system in order for you to find what you are seeking.
Now, you may be saying, “Well I must be a bad botany scholar if I didn’t even try the Dewey Decimal System.” Well, what if I told you the Dewey Decimal System hadn’t been invented yet. And wouldn’t be for another year. It would be another ten years before adaption started. But within 40 years of being introduced, it would be used in 96% of US public libraries.
I believe it is time for APIs to have their own version of the Dewey Decimal System. API’s need to adhere to a generalized format to allow greater adaptation as well as providing a framework for API creators to follow.
Connecting to ten different APIs on a similar topic will result in ten different organizational data structures while they all contain basically the same information.
The Dewey Decimal System is based on a system of categories with a base of ten. Ten categories (main class) have ten sub-categories (the hundreds class), and those sub-categories have ten sub-categories (the thousands class). This framework provided a way for all libraries to organize themselves in a way that allowed anyone to enter any library and understand its structure. Hmmm, this is kinda sounding like a framework using parent child architecture.

Well isn’t that what an API basically is? Well yes, it is, but so were the shelves of a library filled with books. It was just information on shelves tucked away waiting for someone who knew the local organizational code to come and find them. Melville Dewey decentralized that knowledge by creating a standard for librarians to organize by and information seekers to follow.
I believe we are in the early days of API structure. It is the wild west. Some do it well, some do it not so well, BUT it works for them. Data in most cases needs to be predictable. It needs to be organized to allow the user to quickly retrieve the information needed.
Don’t believe me? Take a look at your Documents folder. Now take a look at someone else’s Documents folder. Notice any differences? Which is better? The one that works for you. But public APIs are created for public use, not personal use. And should be structured as such.
In their current form API users need to rely on creator curated documentation, which is often rarely done well, if at all. If there is no documentation users need to use the guess and check method, which is never efficient.
A predicable API data structure would not only allow users a way to traverse data efficiently but would provide a framework for developers to follow to ensure high user satisfaction and design. A predicable format might also afford navigation for “dumber” devices like non-smart phones. Not to mention would provide a navigational code ‘path’ enabling computers to traverse endpoints pragmatically instead of logically.
I understand there are many different data-types and nuances for the specific application which might make this difficult. But I don’t believe it is more difficult than organizing every library in the United States in the late 1800’s without the use of the telephone. It is a shift in thinking in order to make organization of the whole better.
I don’t have a proposed structure per se but I do have a name. HBI. My prediction, in the future APIs will need a HBI to afford easily traversable and organizational structure.
What is a HBI? It stands for Hash-Brown Index. What is the Hash-Brown Index? It is named after my cat, HashBrown. People who create things get to name them and I am staking my claim. HashBrown is an easily approachable cat and people love him, similar to how future developers will love APIs using the HBI.

As I work through the coming modules I will do my best to structure my data in a predicable format and glean any insights. I’ll report back with my findings.
Have you any ideas on how best to organize API data? Please send them to me! J.Tustin@gmail.com
— Joe Tustin